Starting with V10.0, Cora SeQuence has been renamed to Cora Orchestration.
V9.9 and later
Overview
The archiving mechanism helps you meet business and legal requirements for storing and retrieving data. Besides effective maintenance and costs, archiving also enables efficient data management and boosts your system's performance, by keeping the operational database lighter.
Main benefits
- Flexible storage and purging policy configuration
- User-friendly interface to search and retrieve archived data
- Permission-based access to archived data
- Support various storage solutions: Amazon S3 (Simple Storage Service), Azure Files, and network drives
The archiving mechanism extracts data from the operational database and moves it to the archive database, making sure that only operational data resides in the product database. Only users with permissions can view and download archived data. You define permissions when setting up the archive policy.
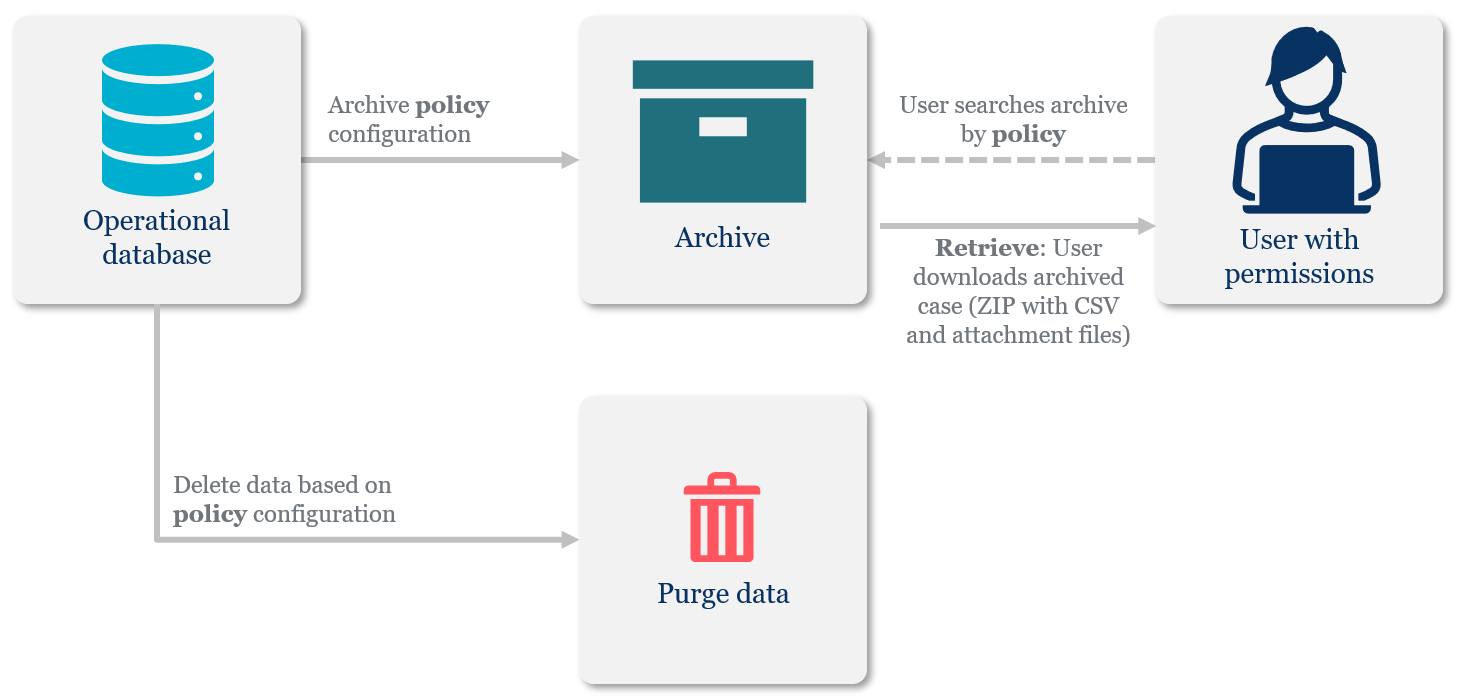
Archiving makes sure that you are complying with the organization data retention policies.
The supported storage types for archive are AWS S3, Azure File Storage and Network Storage.
IMPORTANT
Archiving is irreversible. After archiving, the data is deleted from the Cora Orchestration operational database.
Configuration
The archive feature involves the following components:
| Administration site | Job Execution Service (JES) | Portal |
|---|---|---|
| You configure the archiving policy in the Administration site, at Administration>Archiving>Policy Management. The archiving policy specifies the:
| You configure the following archiving jobs at Administration>Global Settings>Jobs Management.
| End-users retrieve archived data from the Archive page on the portal.
|
Archived data
- Workflow instances that match the archiving configuration settings are referred to as the "archiving population". For example, if archiving is set for one year, then a master workflow that has been closed for one year will be archived along with its sub workflows.
- You can have different archiving configurations for different workflow spaces according to variables and time filters. The archiving is performed per master workflow instance ID.
Excluded data
- The archiving configuration allows you to exclude some workflow templates and tables from archiving. These excluded items are not archived even if the policies define them as part of the archiving population.
- You configure archiving exclusions at Administration>Archiving>System Exclusions.
Deleted data
- Data that has been archived is permanently deleted from the operational database.
- You can configure a policy that deletes unnecessary data without archiving it.
For details on setting archive policies and configuring the archive jobs, see this article.
Deployment
The archive feature is deployed with the applications. There are no special procedures.
Make sure that the archive database or storage location is set up before you configure archiving policies.
Data retrieval
When archiving is configured in the system, portal displays a new menu item that opens the Archive page. Only users with the required permissions can access archived data.
In Flowtime (V9.9 and 9.9.x)

In Portal (V10.1 and later)

The user can reorder, sort, and filter the Archive grid. The case ID, Completion Date, and Archived At are default columns. You can define additional columns when you configure the archive policy.
The column Archived At is available in the grid from V10.6 onwards.
From V10.6 onwards, the archive grid also has an option to export to Excel.
The user downloads the archived case in a ZIP file that includes all the case related data like images and documents in their original format and data files in CSV format.
The ZIP file includes four folders:
- Files: Contains all the files related to the case and a JSON file with the case's metadata.
Naming convention: <GUIDID>_<filename> - Tables: Contains all the default tables and custom tables specified in the policy in CSV format. It also contains the tables' JSON and the tables' metadata JSON.
- ConversationView: Contains all the Conversation View items of the case. Available from Cora SeQuence V9.9.1, and for Cora Orchestration V10.2 onwards.
From V10.5 onwards, the conversation items are available in .EML format also. - EmailView: Contains the emails that were sent from the case. Available from Cora SeQuence V9.9.1, and for Cora Orchestration V10.2 onwards.
From V10.5 onwards, the sent emails are available in .EML format also.
You can customize the Archive grid's look and feel.
